Carrier layer
SIP response paths, setup timing, retries, and teardown sequence reveal carrier-side behavior that impacts initial connection and stability.

Resource — Observability
Telepath gives teams direct evidence across signaling, transport, gateway timing, and AI response timing. Instead of debating possible causes, you can isolate what failed and where it failed, per call.
SIP response paths, setup timing, retries, and teardown sequence reveal carrier-side behavior that impacts initial connection and stability.
Media bridge timing, packet handling, and lifecycle events show whether transport boundary performance introduced delay or degradation.
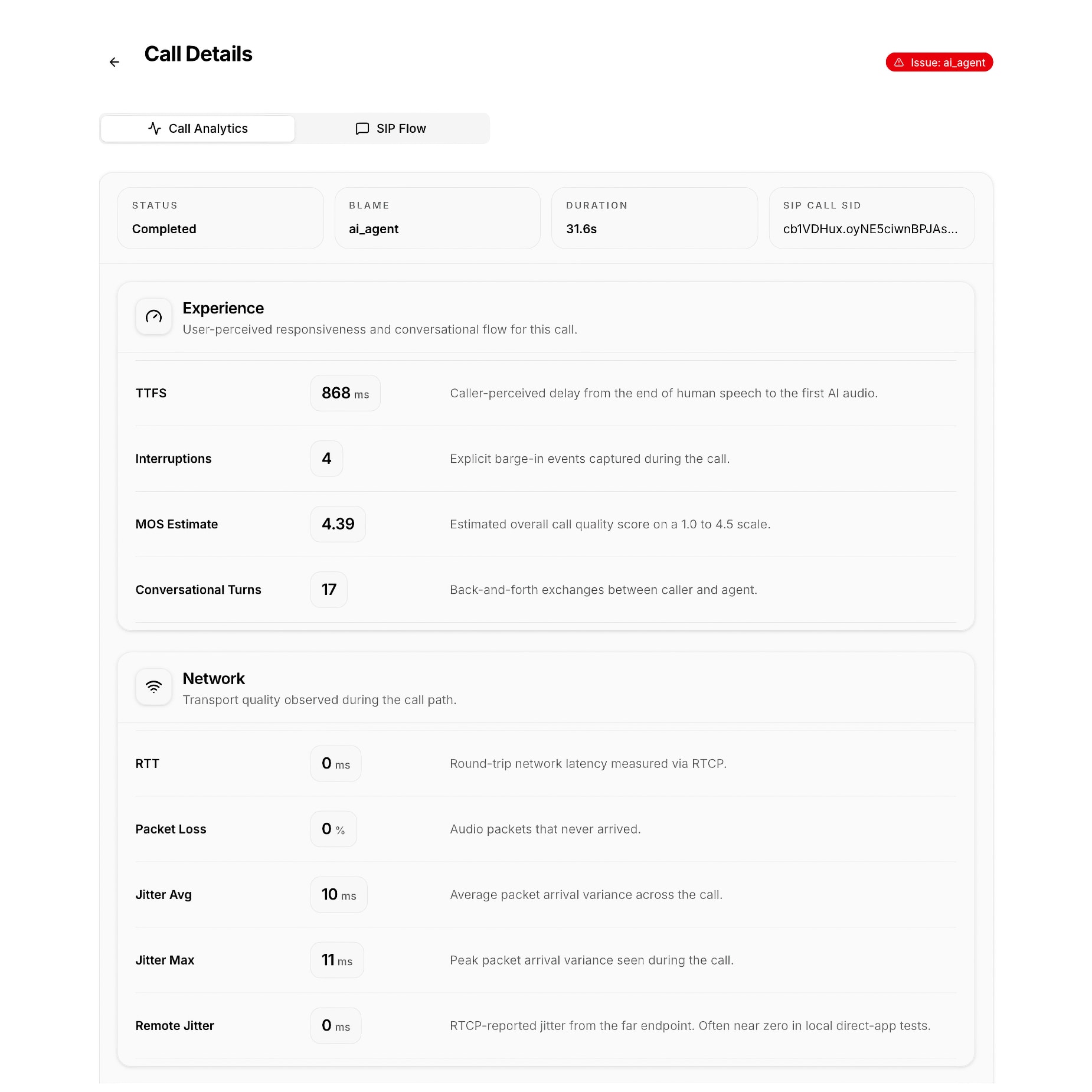
AI first-audio timing and per-call experience metrics separate model-side responsiveness from network-side behavior.
AI voice deployments involve at least three distinct infrastructure layers under different ownership: the phone carrier (Twilio, Telnyx, etc.), the media transport layer, and the AI runtime (Vapi, Bland, Retell, or custom). When a call has a problem, the first question is always which layer caused it. Without per-call evidence that spans all three, the answer requires either guessing or a multi-party war room.
The classic failure mode looks like this: a caller reports that the AI agent was slow and then disconnected. The team checks the AI platform’s logs, which show the model responded normally. The team checks the carrier console, which shows the call completed. Nobody can find what went wrong. The actual failure was a carrier-side SIP re-INVITE that caused a brief media interruption, which the AI agent interpreted as an end-of-session event. Without SIP flow data and RTP timing from the transport layer, this is invisible.
Effective AI voice incident triage follows a consistent sequence: start at the signaling layer, move to the transport layer, then evaluate the AI layer. This order matters because lower-layer problems mask higher-layer diagnostics. If the carrier SIP setup was abnormally slow (500ms INVITE-to-answer), that alone can explain a caller’s complaint about the call feeling unresponsive, without any model-side issue at all.
Signaling layer: look at the SIP ladder. Was the INVITE answered promptly with 100 Trying and 180 Ringing? Were there auth challenges or retries? What was the timing from INVITE to 200 OK? Did the session terminate with a clean BYE or with an error response? Each answer narrows the scope of the problem significantly before you look at anything else.
Transport layer: once signaling looks normal, examine RTP packet quality. Was packet loss elevated during specific intervals of the call? Did jitter spike, and if so, when? Was the gateway processing time within the expected range? These metrics tell you whether the media path was clean or whether something degraded the audio delivery to the AI agent.
AI runtime layer: if signaling and transport were clean, the issue is most likely in the AI layer. Look at TTFS per turn. Did response latency increase over the course of the call? Were there specific turns where the agent took longer than normal? This points toward model inference conditions, context window growth, or TTS synthesis delays rather than anything network-related.
When you need to escalate a quality issue to a carrier, the difference between “callers are complaining about dropped calls” and “here is a SIP ladder showing your media server sending a 481 Call/Transaction Does Not Exist response 4.2 seconds into 23% of calls originating from your US-East SIP proxy between 14:00 and 15:30 UTC last Tuesday” is enormous. The first gets a templated response. The second gets a network engineer looking at specific infrastructure. Telepath’s call-level artifacts are built for the second kind of escalation.
Click to view each artifact at full size. These are the exact views engineers use in incident triage and postmortem analysis.
Move from anecdotal debugging to a structured sequence: signaling, transport, gateway, then runtime. The triage path is defined, not improvised.
Use call-level evidence to document failure mode, confirmed root cause, and remediation. Postmortems become engineering documents, not guesswork summaries.
Share concrete traces and timing artifacts with carriers and AI providers instead of unsupported symptom reports. Evidence-based escalations resolve faster.
Telepath provides structured call-path diagnostics while preserving your existing carrier and AI choices. You get faster attribution without changing your full stack.